How We Improved Data Sync Performance By Over 30x

Integrating bespoke online applications with existing internal systems is a key challenge that a significant number of Evoluted clients engage us for. These range from custom integrations with CRM systems, on-premises databases, air-gapped factory systems and a thousand other solutions in between.
In an ideal world our bespoke solutions would communicate seamlessly with them via modern, robust protocols. Unfortunately the real world isn’t so forgiving! This means we often have to settle for pulling a copy of data from these systems asynchronously.
Data syncing like this is rarely the best solution, but sometimes it’s the best available solution.
Let me give you a working example to explain:
A client wanted to transform how they sold to their customers by providing an online store alongside their established telephone and postal processes. Simple in theory, right?
But, their on-premises software managed pretty much everything, from manufacturing orders right through to invoicing. Powering the online store with that system would have meant making it externally available and a lot more performant which was, at the time, unfeasible.
So we made the decision to run the store from a subset of that data that we would regularly pull from the source database, and any interactions - customer orders, address updates, new contacts etc. - would be pushed asynchronously via various channels. Our sync then ideally had to be fast, timely, and accurate to ensure a seamless customer experience.
However, the journey to that ideal scenario took a few versions…
Version One
The first attempt was the simplest: load all the source data into memory and iterate through it, writing it to our target database.
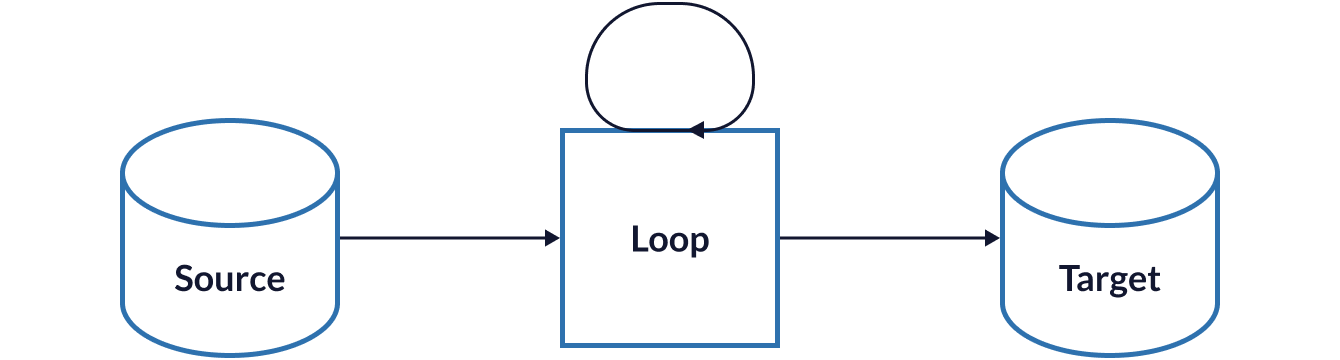
For small data sets - up to a few thousand records - this method worked well and engineering anything beyond this was going to be wasted effort. The most prominent issue this approach suffers from is that any complications with the source data (and there absolutely were complications) will stop processing of the entire set.
So an issue on record 2 of 1,000 will mean 998 records won’t be processed until that issue is sorted.
When starting out this wasn’t a huge obstacle as we were still working out the shape of the data that the online store needed, so continuous iteration was par for the course.
Discovering that users in the source system weren’t required to have a unique email address was somewhat of a surprise though, especially as that’s critical for customers of an online store. We found fields we assumed to be required were often missing in various ways: sometimes null, sometimes empty strings. Fields were often noisy with assorted formats for telephone numbers and compound names, or they had surrounding whitespace from when it was input or just from fixed length database columns. Like an archeological dig we kept unearthing more gotchas and historical inconsistencies.
After a lot of back and forth and trial and error our data sync stabilised, alongside working with the client to improve their processes for entering and updating data.
Version Two
The next dilemma though was that our sync was slow. The number of available products rapidly increased and the time to finish a sync grew. Version one ran console commands on a cron schedule, and with something like parallel we could have pushed this model further, but the Laravel framework has first-class support for queued jobs so it made sense to shift the syncing logic to them.
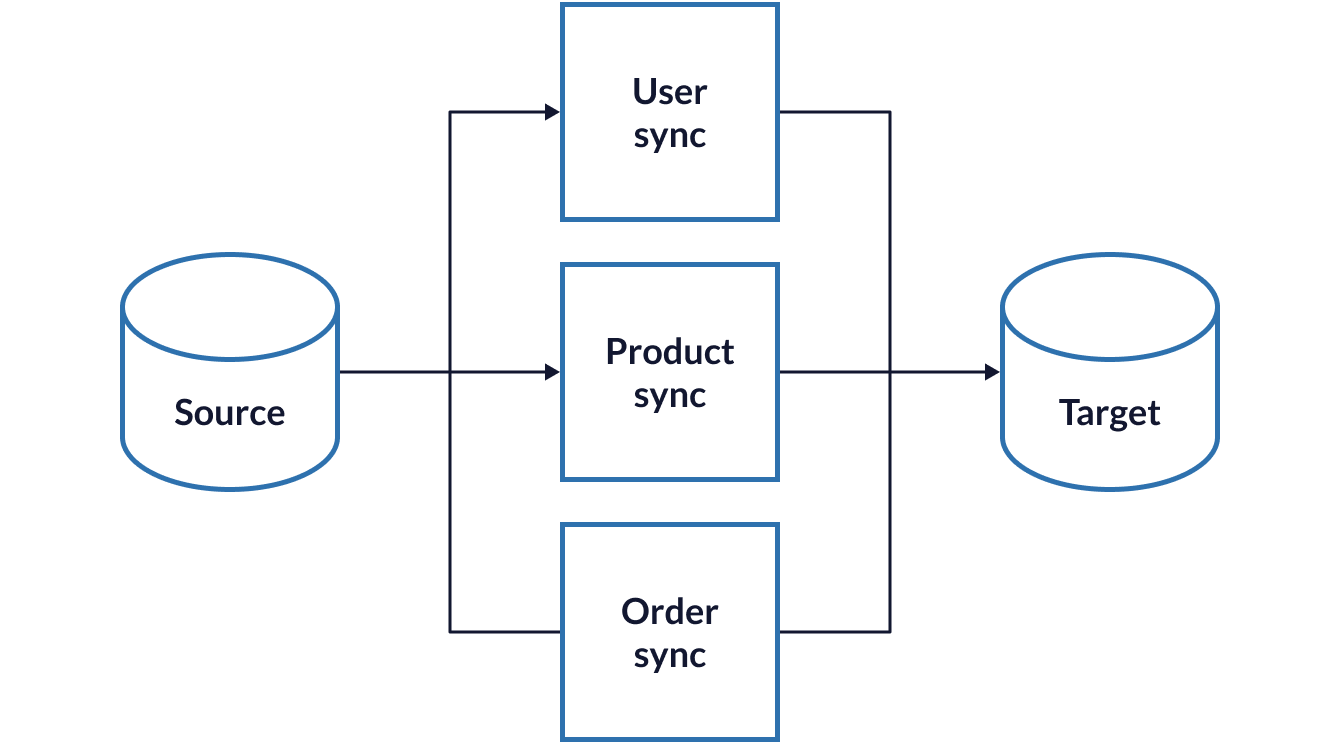
Doing this gave us control over the concurrency of different jobs - the data sync was becoming a more resource intensive process and we didn’t want to starve out any other processes.
Version one already had Sentry alerts so we didn’t lose any visibility of issues that cropped up which can often happen with queue jobs. At first we used the Symfony Lock component to ensure that we weren’t running the same sync multiple times, however Laravel introduced a native solution in version 8.0. The downside of both these solutions however is that if an unexpected error does occur, you either have to wait for the lock to expire or manually remove it before another sync will take place.
Moving to queued jobs however didn’t sort the amount of time certain syncs took: 4.8 million stock units is a lot to process sequentially, even with more control over resource usage and concurrency.
After an extensive performance audit, we began more smartly batching updates and being more judicious in our filtering, making sure that we only updated the target when the fields in the source had changed. By trading database load for CPU usage we markedly improved the sync’s runtime, from twelve hours to four. Even with this improvement, if a new product went live on the client’s system at 9am, it might not appear in the online store until 1pm.
So back to the drawing board it was.
Version Three
Parallelising the process was the obvious next step to improve performance, so taking those 4.8 million stock units and breaking them up into batches of 1,000 units each, each batch able to be worked on independently. The source database however did not have a lot of resources to spare, and because it - without hyperbole - ran our client’s entire business, tying it up with an aggressive data sync would directly impact their ability to function day-to-day.
This meant when batching the data we needed to be prudent with our interactions with the source database. Consistent batching though was not going to be straightforward. A naive approach to get 1,000 rows would be to query the source database for IDs between 1 and 1,000. This might return 1,000 rows or it might return 10, as anyone who has used auto-incrementing database keys will know, there can be gaps. This would make its resource usage very “spiky” as well as increasing the number of batches it would take for a full sync.
Thankfully, SQL has the answer in the form of window functions, specifically the very handy ROW_NUMBER function:
SELECT t.id
FROM (
SELECT stock_units.id AS id, ROW_NUMBER() OVER (ORDER BY stock_units.id) AS row_num
FROM stock_units
) AS t
WHERE (t.row_num % 1000) = 0
ORDER BY t.idThis “batch” query will return a list of IDs that if used in a subsequent WHERE clause ensures we’ll always get (close to) 1,000 rows. So if the above query returns 10387 and 14976, this query:
SELECT stock_units.* FROM stock_units WHERE stock_units.id >= 10387 AND stock_units.id < 14976Should return 1,000 rows, and because the WHERE condition only uses the primary key, this query should be very performant. Any JOINs or other filtering do need to be fed back into the first query as well though to make sure the ID ranges you get back are accurate.
The “batch” query meant that larger syncs could be broken up into smaller, consistent syncs that, critically, can be run in parallel.
Further to this, the sync process was broken down further into different stages to improve testability and code reuse, as well as to better manage our connection to the source database.
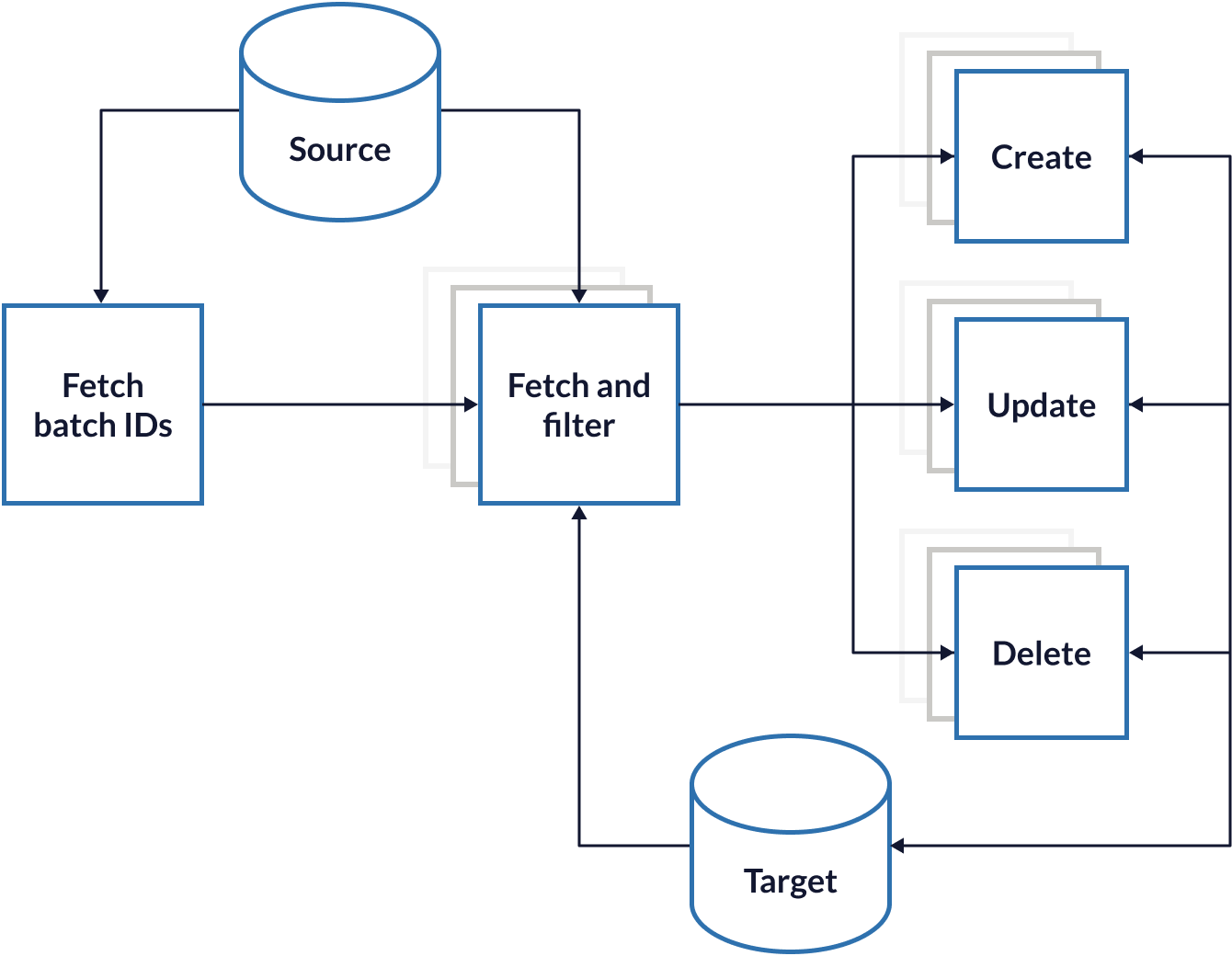
After retrieving the batch IDs, “fetch and filter” queue jobs retrieve the data from the source database, then filter it for further processing using the same heuristics developed in version two. Separate jobs are dispatched to modify the target database to match the source.
Once the fetch and filter job has completed, the connection with the source database is released and reused ensuring we’re not tying up resources. The discrete create/update/delete jobs enable us to prioritise new products to ensure they’re added as soon as possible, whereas deleting old products is less important and deprioritised.
Parallelising this process immediately improved runtime, taking a twelve hour run time in version one, an average three hour run in version two, down to 22 minutes in this version. That’s a “hot” run, when the delta between the target and source data is relatively small, something that is easily maintainable now the runtime is much shorter. Starting with an empty target database still takes several hours, but crucially doesn’t use any more resources on the source database.
From the client’s perspective this performance speed up meant the online store was more current and any updates were more timely, but also meant the sync was overall more robust as an unexpected issue in one batch wouldn’t affect any other.
As a foundation, this setup made further development much easier meaning that new syncs - stock levels, due dates, order updates - were implemented quicker and with fewer errors. This comes at the cost of complexity though with far more moving parts and places to debug when issues arise.
Mapping
Version two’s performance improvement work necessitated the creation of a map in the target database connecting the internal target IDs with the source ones, as well as the last time it was synced. Originally this data was spread across the target database as extra fields on each table e.g. “source_id” and “last_synced”; however this not only cluttered up every table but also didn’t fully capture instances when there wasn’t a clean 1:1 mapping between the source and target records.
Any sync action then touches both the target table and the mapping, opening up the possibility of duplicates and orphans, compounded by any manual database modifications.
These can be solved with automated maintenance and table triggers however that shifts development away from version-managed code and into the database, requiring new testing, documentation and maintenance methodologies.
Takeaways
While working on the different versions of the data syncs, some key points surfaced:
Notify when problems occur
Engineers tend to overstuff their logs when starting out with data syncs. Logs are valuable but only after a problem has occurred and they often don’t get checked if everything seems to be working. Incident trackers like Sentry complement logs by putting issues in front of engineers as soon as they happen.
Only notify when manual intervention is required
One common issue we had was trying to sync something before its dependencies were present. This is a timing issue so it sorts itself in subsequent runs; so for issues like these there’s no need to notify as it’s just noise and lessens the impact of when a “real” issue happens.
Do as much at the source as possible
For us the source was another database so we used SQL to trim fields or ensure nulls didn’t surface, but other systems like GraphQL allow rich data modification as well. It means your code is slimmer and less prone to errors.
Write processes for common tasks
We found that knowledge about the data syncs tended to get siloed, so if an engineer was on annual leave, no one knew how to “unstick” a queued job; creating a playbook for these sorts of tasks has been invaluable.
Future
Version three, with some quality-of-life tweaks, has been in production for over a year now and has shepherded the client’s digital transformation project to its next phase: retiring the on-premises database.
A significant part of the functionality we’ve packed into the sync is now available via REST APIs, obviating our dependence on the source database. The source of truth for the online store and its offshoots is no longer split across disparate servers and networks.
What would version four have looked like though?
Version three minimised a lot of the downsides to syncing large sets of data so perhaps a new paradigm could improve the development experience. The idea of data syncing isn’t new, so perhaps a framework around an Extract, Transform, Load (ETL) pipeline would work - there are certainly enough PHP packages that facilitate it.
Or maybe using Postgres’s foreign data wrappers (FDWs) to load the data, or SQL Server’s service broker to capture changes?
Time will tell as we continue to iterate in collaboration with the client and I look forward to tackling whatever new challenges come our way!

In his role as Technical Team Lead, John’s expertise is vital to our development approach across several large-scale projects. He arrived at Evoluted in 2019, having worked in various roles for several local agencies, and now has almost two decades' experience in the industry. His primary skills are providing insight into architecture, scaling, dev-ops, deployment and security.




